
That tiger — and the little avian dinosaur in the foreground, keeping a respectful distance away from the cat — are walking along one of many river beds that cross the Terai, a flat grassy wetland that runs along the feet of the Himalayas in Bhutan, India, and Nepal.
This particular river is in Nepal, according to the photographer.
As you can see, Terai soil is deep and fertile, but mountain floods can slash through it easily. They also bring down the nearby towering range piece by piece as rounded boulders and cobblestones.
Thanks to plate tectonics, though, the Himalayas continue to rise despite this constant assault by rain and ice.
Down in the flatlands, a young Ganges River flows through the Terai, gathering in lesser streams like the one shown above and growing in size and volume as it travels more than a thousand miles eastward and then south to the distant Bay of Bengal.
India and Nepal established important nature preserves here in the early 1970s. Bengal tigers are also protected elsewhere in the region, including the Sunderbans: a vast mangrove forest that covers the Ganges Delta of India and Bangladesh.
What does all that have to do with plate tectonics?
Well, this:
A few caveats to this excellent video: Per sources that I have read, other factors were also at work during the great greenhouse-icehouse transition, but let’s save that for Chapter 18. As I understand it, there is consensus on the evolution of whales, but otherwise the India-Asia collision and its effects on plant and animal life were very complex, as this abstract shows. Not all experts agree with Dr. Hughes. In a later chapter, though, we’ll look into another, even more controversial hypothesis: that big cats might have evolved in Tibet!
Cats and Plate Tectonics
Take the part in this video where they mention cooling, for instance.
Based on how cats behave now and the ways that behavior has shaped their anatomy and that of their fossil relatives down through time, it’s likely that Family Felidae evolved to fill a predator niche in an ecosystem that existed in between the forest’s edge and an open plain. (Martin).
That was ideal! There was sufficient cover to sneak up on prey (and trees to scoot up into when danger threatened), as well as just enough open space for a short sprint and deadly pounce. (Werdelin)
Now try to imagine a place like that in Late Cretaceous times.
Despite what you’ve seen in the “Jurassic Park” movies (Akhmetiev and Beniamovski; Prothero; Vajda and Bercovici), it might not have existed:
- The non-avian dinosaurs’ world was warmer and muggier
- Much of what is now land was covered in water back then, with the central plains of North America and Eurasia hidden at times underneath warm, shallow seas
- Vast swamps were turning into thick coal beds
- Per the best-known fossil record of those times (North America’s Hell Creek Formation), a rainforest grew in what’s now North Dakota
A surprising and, in some ways, delightful world, but it was no place for a cat.

The difference between that world and our own is distinctive. (Image: Bureau of Land Management, CC BY 2.0)
Any clearings that opened up from fire, storms, or “veggie-saurus” overgrazing probably filled in quickly with a jungle-like tangle of plants competing for light.
Of course, the K/T (K/Pg) extinction 66 million years ago changed everything for animals and plants, but it didn’t turn Earth into an icehouse.
Plate tectonics, as described in the video about India, as well as other factors (Lyle et al.) did that.
Plate motion, however, is slow, so global climate took millions of years to cool off and dry out.
A decent habitat for stalk-and-pounce predators only developed at around the 35-Ma line in our cat/sports field analogy.
And the first cat-like mammal predators — nimravids — then showed up.
We are jumping way ahead of the story here, but it’s also interesting to see how plate tectonics helps us answer other questions about cats.
For instance:
- Since Earth is obviously an ocean world (Taylor and McLennan), why did we (and cats, among many other forms of life) evolve on dry land?
Answer: Because there has been continental crust on this planet, as well as seafloor, for almost as long as Earth has been around. (Morton; Sleep) Marine life of some sort came first, but Life started exploiting the vast resources available on land just as soon as it could.
- Why did cats first show up in the Northern Hemisphere? (Werdelin et al.)
Answer: Because once they came on the scene in Eurasia roughly 30 million years ago (Werdelin et al.), cats couldn’t swim across oceans to get into the Southern Hemisphere. Plate movements first had to form land bridges with Africa (about 19 million years ago) and South America (some 3 million years ago). Australia is still isolated; cats arrived there just a few hundred years ago by ship along with Europeans. (Agusti and Antón; Prothero: Werdelin et al.) - Why are there so many hybrids among small wild Latin American spotted cats?
Answer: Okay, that question might not occur to you unless you’re into wildlife conservation or have read my ocelot lineage eBook.
They really are adorable. (Image: Márcio Motta, CC BY-NC-ND 2.0)
Trust me: Even experts have a difficult time sorting out pampas cats, tiger cats, and some other species.
These little cats reached South America so recently that some of them haven’t completely settled into stable species yet.
Sure, 3 million years is a long time to you and me, but evolution, like plate motion, takes time. These beautiful kitties are still undergoing what biologists call an adaptive radiation.
Genome research shows that similar hybridization occasionally happened in the distant past with other feline lines, like 10-million-year-old Panthera (the big cats). (Figueiró et al.; Werdelin et al.)
For that matter, mammals — particularly our group, the Eutherians — had a huge adaptive radiation after the K/T (K/Pg) extinction. (Prothero)
This is one of the ways that evolution works.
Plate tectonics and climate
We just saw how plate tectonics built land bridges and changed world climate in ways that helped cats to evolve and migrate.
So plate tectonics is a player in this series about Family Felidae.
To explore it, though, we need to strip away vegetation and other forms of life that we usually think of as “the natural world” and look at the underlying raw power of Earth as shown by things it has wrought.
That’s not easy, since the planet is much bigger and older than us.
Without these seemingly eternal mountains, there would no tiger and bird standing in a dry Nepalese river bed, no Ganges, no Sundarban mangroves, probably far fewer people in India and parts of Asia, and a VERY different global climate. Today, humanity provides an exclamation point to Himalayan grandeur, but how did Life ever get started when the whole world was so stark and silent?
Although it operates on geological time scales, plate tectonics is the force behind earthquakes and eruptions and other changes that disrupt our daily lives.
It also underlies the whole field of physical geography, which covers natural features that shape evolution and human society in many ways.

An ever-changing “blue-and-white marble” — complicated almost beyond human comprehension? Who would have expected that! (Image: NASA)
Plate tectonics is also part of an interwoven geologic/atmospheric/hydrological planetary systems network that affects us all personally.
We need to take that seriously.
Like me, you’ve seen and perhaps also have been turned off by the news coverage of “climate change.”
It isn’t pretty: political fighting over policy never is, because no one is ever objective and everybody’s ugly side comes out.
Just for the record, I think it demeans Science whenever any of its members use labeling like “denier” on those who disagree with them, rather than undertaking the difficult task of calmly reasoning with them to open their minds.
Unfortunately, there is a lot of that going on, and it’s just as unhelpful as the other side’s unrealistic view, basically summed up as “so what?”.
Cutting past all the mean stuff, scientists do know something important that the rest of us don’t: our dynamic Earth goes through some intense climatic “mood swings” over geologic time.
Unfortunately, because this involves multiple factors and feedbacks, including but not limited to plate tectonics, no one can be very certain about the why and how of it.

Venus, top, by NASA/JPL-CalTech: Saturn’s ice moon Enceladus, bottom, by NASA.
One of the more extreme of these episodes, when the planet was more or less completely iced over, was the Cryogenian.
It happened about 1 billion years ago. You might have heard it called “Snowball Earth.” (There were actually several such events, but only the most recent one — the Cryogenian — has left much evidence; we’ll get into that a little later in this post.)
Life on Earth survived the Cryogenian and actually went into the famous “Cambrian explosion” after the last traces of its globe-covering ice melted away.
But the hellish conditions on our “twin,” Venus, clue us in that other, more lethal extremes than a deep freeze are possible on the planetary climate spectrum.
Earth might have been like that in early Hadean times, soon after its formation (Morton), but not since then.
As we’ll soon see, plate tectonics stopped that runaway greenhouse by cycling carbon dioxide into Earth’s mantle. (Sleep)
The third planet from the Sun has had other, milder “mood swings,” like the global greenhouse conditions that non-avian dinosaurs enjoyed or the icehouse that we have today.
Changes from one “mood” to another can happen fairly quickly.
The geologic record shows that conditions cross a threshold of some sort and — just as one example — soon, global CO2 somehow nosedives and you’ve now got ice on Antarctica (Lyle et al.) — a continent that often was habitable during its long history.

This fossil leaf grew on a bush- to tree-sized fern in Antarctica during the Permian. (Image: James St. John, CC BY 2.0)
It’s only a little ice at first, but the delicately balanced climate mechanisms and feedbacks have shifted; one thing leads to another, and eventually Antarctica is deeply frozen, while continental ice sheets are moving back and forth over the world’s other polar land masses every hundred thousand years or so. (Lyle et al.; Prothero; Zachos et al.)
No one yet knows much about the world thermostat and its thresholds, other than that when Earth crosses one of those, the environment changes in complex ways and there is nothing we can do but get ready for the consequences.
While few of us would be distraught if there never was another Pleistocene-style ice age, sea level rise and climate shifts during the transition out of an icehouse “mood” would play expensive and often deadly havoc with our carefully arranged artificial world.
We might be seeing the start of that now, although the sociopolitical static around this hot-button issue makes it impossible to be truly objective. Time will tell.
And there’s this to think about, too: Although greenhouse gas levels are still quite low compared to those at some points in Earth’s history, we are the Pleistocene’s children.
How well will we do at another another planetary “setting”?
Quite well, I suspect, given our adaptability and technology, but there is also the question of how Earth’s regulatory systems will react to the extreme climate forcing that humanity is unloading on them today.
What climate thresholds might we unwittingly drive the planet across, with potentially dreadful consequences?
We just don’t know. Earth’s experiment in the evolutionary viability of advanced intelligence has only been going on for a few hundred thousand years — it’s too early yet to tell whether that will be successful or a dead end.
So let’s think about cats instead — well, at least about the point where we left off in this series.
There weren’t any cats yet, but young Earth, a little more than 4 billion years ago, had cooled enough to have a fairly solid mantle, as well as an outer crust covered with oceans that were kept filled by a water cycle that operated in a smoggy, methane/CO2 atmosphere that would kill us with a single breath.
Earth compared to other planets
When we last visited Hadean Earth, a few hundred million years after its formation, the magma ocean that had covered this planet’s surface had cooled off and crusted over, while the mantle underneath it was “freezing” into rock from the bottom up.
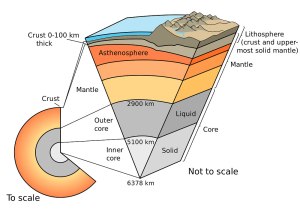
That’s not to say Earth’s mantle was ever totally solid. It’s not rock-solid today, when temperatures down there are much cooler than they were in Hadean times: gigantic currents of hot rock still convect through the mantle just as if it was a simmering pot of soup on the stove.
Chemical and physical differences aside, simmering soup actually is a good analogy for the mantle — and not just because solids (crystals), liquids (magma), and gas (water vapor and other volatiles) are combined down there (Oppenheimer) like meat/vegetables, broth, and savory steam in a stew.
After all, the mantle’s base is in contact with an extremely hot stove burner planetary core.
And this is what some of that “soup,” a/k/a the upper mantle or asthenosphere, looks like on those rare occasions when it bubbles over. This eruption is in Iceland — a special case.
And the pot lid? Today it’s Earth’s lithosphere — continental and oceanic crust.
Back in the Hadean, it was crust that formed when the magma ocean cooled down, right? Sort of like the dark scum that eventually covered Kilauea Volcano’s cooling 2021 lava lake?

Well, no doubt that old magma ocean crusted over like that at first.
However, newborn planets and other large rocky worlds apparently have alternatives as their thick outer layer hardens up.
And two of the three types of crust that Taylor and McLennan describe apply to Earth at different stages in its development.
According to these experts, a planet or moon’s outer crust can be:
- Primary: Material from the Solar System’s formation. As it cools, some minerals crystallize early and float to the top: for example, this is how Taylor and McLennan say that the light-colored lunar highlands formed.
The rock/ice outer layers of some Jupiter and Saturn moons might be primordial, too.
There was recent news from Greenland about the discovery of 3.6-billion-year-old crust from the Hadean magma ocean. I don’t know how that fits in with widespread consensus that 4-plus-billion-year-old zircon crystals from Australia’s Jack Hills show evidence of continental weathering — something unlikely to happen when there was a global magma ocean. (Palin and Santosh; Sleep; Taylor and McLennan)
- Secondary: Internal heat from radioactive decay melts part of the mantle, causing basalt eruptions on the primordial crust: think the dark parts on the Moon — the lunar maria.
Another example is Jupiter’s moon Io; here, the heat also comes from interactions with Jupiter’s immense gravity field.Palin and Santosh see this Jovian moon as a possible analog for very early Earth, although Io is much smaller. If that’s the case, then such lava flows would have buried the original crust that hardened over our world’s Hadean magma ocean.
By the way, Taylor and McLennan include Mars and Venus in this category.
So do Palin and Santosh, but they point out some unusual details, like relative young volcanism on Mars (less than 40 million years old) and an unknown catastrophe on Venus that resurfaced the entire planet some 300 million years ago, as well as a few peculiar surface features on both planets (see the discussion in their paper).

An eruption on Io, while the Galileo spacecraft was passing by. (Image: NASA)
Details aside, the above examples are both forms of what geologists call single-plate or stagnant-lid tectonics.
There is only one known example of Taylor and McLellan’s third type of planetary crust, and we’re living on it right now:
- Tertiary: Another name for this is mobile-lid tectonics, or as most of us call it, plate tectonics.
Taylor and McLennan note that, as the planet’s surface layers recycle down into the mantle, “continuous distillation” produces magmas that are more like granite than basalt — in other words, the continental crust of today.
Note that this isn’t as dense as basalt seafloor, so it doesn’t go down into the subduction zone.
Instead, depending on relative plate motion, this crust either piles up into something like the Himalayas or else slips sideways, as those parts of California west of the San Andreas Fault are doing right now.
Exactly how and when plate tectonics began is an unsettled scientific question, but it must have required many favorable factors, most notably, the long-term presence of water on the surface. (Palin and Santosh)
Why?

Get your license first.
You try subducting a dry rock plate some time!
It can’t be done. Friction is too strong, and the plate also won’t be bendy enough for the move. (Palin and Santosh)
Earth’s mantle outgassed water vapor as it “froze” during the first 10 million years or so of the new planet’s existence, so there was plenty of water available in streams and oceans to get a stable hydrologic cycle going. (Zahnle et al.)
Something similar probably happened as Mars and Venus also cooled down. Venus might even have been the Solar System’s first habitable world! (NASA, 2021)
But those worlds didn’t have water for long. And the Moon lost all its volatiles, including water, during its formation during a gigantic impact. (Sleep)
So, until space scientists prove otherwise, it seems that Earth’s being a long-term ocean world has also made it the only Solar System body to have plate tectonics.
Is that also why it hosts life?
That question is much bigger than it appears to us laypeople, judging by the number of research papers found on Google Scholar that address it and related topics.
From the little I’ve read, some models reportedly suggest that single-plate worlds could hold on to water for a long time. This implies that simple life might possibly exist elsewhere.
But this did not happen on Mars, and space scientists still wonder about Venus.
There might be a broader consensus on this point: complex life is possible only on a planet that has plate tectonics. (Palin and Santosh)
One reason for this is that plate tectonics, besides keeping greenhouses gases down, also recycles essential nutrients for life. (NASA, 2020b)
The rock cycle
At first, on Hadean Earth, only water and carbon cycled through various stages:
- Mantle outgassing formed oceans, whose surface waters evaporated into vapor that eventually condensed into rain and made its way back to the sea — the hydrologic cycle.
- That rain water chemically interacted with CO2 in the air to form weak carbonic acid that leached minerals out of the rocky ground when it fell and brought everything into the sea, where further reactions turned it into carbonate rocks — the carbon cycle.
But apparently rocks were cycling, too.
The oldest minerals on Earth — those 4-plus-billion-year-old Australian zircon crystals — are from metamorphosed clay-like sediments. (Sleep)
This sort of thing was NOT supposed to be going just a couple of hundred million years after the Solar System formed, while the planet was so hot and primitive:
Yet this, or some similar process, obviously was happening together with the water and carbon cycles.
While its origins aren’t clear, whatever was going on with Hadean rocks eventually became the plate tectonics we know today.
But metamorphism and other geologic changes have ruined the few stony archives that have survived from those times, leaving only chemical clues about that Hadean process, like isotopes.

Ruby, by Stranger Than Kindness via Wikimedia, CC BY-SA 3.O; Uncut diamond, by USGS via Wikimedia,public domain; Mayan jadeite amulet, by Metropolitan Museum of Art via Wikimedia, public domain.
There are sometimes clues about plate tectonics in precious stones, too. Jadeite and ruby, for example, are only found in subduction-zone settings and can be billions of years old.
Diamonds — crystallized carbon — are the most famous ancient gemstones; and since they form at depth, perhaps from subducted carbonate seafloor rocks, diamonds also record changes happening in the mantle underneath continents. (Palin and Santosh; Sleep; Stern and Miller, 2018, 2021)
These clues can be, and often are, interpreted in very different ways.
When did plate tectonics start?
Carbonate rock formation in Hadean oceans removed some CO2 from Earth’s runaway-greenhouse atmosphere (Zahnle et al.), but not enough to shut that down or even to cool things off very much.
Scrubbing that much carbon dioxide out of the air was a job for global plate tectonics, which can store vast amounts of carbon deep underground. (Sleep)
But for a few hundred million years, at least, early Earth was too hot to make sturdy enough tectonic plates for subduction.
Yes, there were continents, almost from the get-go, though probably not like the ones we know today. (Morton; Sleep)
Even so, all you could get back then with such a thin, weak crust was overturn like this:
As seen on Kilauea’s 2021 lava lake, when it was fresh.

View through Kilauea summit webcam B1, August 14, 2021.
I like to think of the islands of basalt on that lava lake as similar to early Hadean continents, but don’t quote me on it.
The experts that I’m basing this section on — Morton; Palin and Santosh; Sleep; Taylor and McLennan — only report that there was a change in the old continental material, around 2.5 to 3 billion years ago, from basalt-like mafic rock to more granitic rock.
At that point, the planet’s crust would have been cooler and thick enough to maintain active subduction zones.
Since granite is the sort of material produced by the “continuous distllation” process of modern plate tectonics, most experts believe that is when it all started, 2.5 to 3 billion years ago.
Palin and Santosh explain earlier evidence of an active rock cycle, like the Jack Hill zircons and certain multi-billion-year-old gemstones, as the product of localized tectonic movements that hadn’t yet gone global.
(A note for continuity: Don’t forget that, as we saw in earlier chapters, the oldest fossils known are 3.5-billion-year-old cyanobacteria — Life somehow was doing its thing, at least in simple ways, while Earth’s surface matured.
This might not have been coincidental, per Hazen, who writes “Minerals and life coevolved, with most mineral species mediated by life…”)
There’s an even wilder idea about early plate tectonics out there.
A small but vocal minority argues that the start of mobile-lid plate tectonics would have had much more significant effects than anything found to have occurred 3 billion years ago. (Morton: Stern and Miller, 2018, 2021)
While everyone seems to agree that early plate tectonics subducted away most of the carbon dioxide left over from planetary formation — leaving what Sleep calls “a modest concentration of CO2 in the air and the ocean” — Stern and Miller think that the start of plate tectonics did much more than that.
They also claim that this happened much later in the planet’s development, when the geological record indeed does show a major upheaval.
In brief, Stern and Miller suggest that the development of plate tectonics happened around 1 billion years ago and caused such massive changes in young Earth’s previously stable climate and oceanographic systems that our planet went into what I referred to earlier as a “mood swing.”
That is, about a billion years ago — when plate tectonics began, according to Stern and Miller — Earth froze up, with ice all the way down to the Equator.
This has definitely happened, and more than once over geologic time.
The only disagreement about the most clearly documented event, 1 billion years ago, is whether it was a “hard” Snowball Earth — a solid ice shell — or a “Slushball” Earth with some patches of open water, perhaps in the tropics and/or around volcanoes. (Corsetti et al.; Hoffman et al.; Moczydlowska)
(Continuity note again: Life soldiered on through this, too.)
Why Earth froze over is another matter. There are more than twenty hypotheses floating around besides the one proposed by Stern and Miller, most of them unrelated to the question of when plate tectonics started.
Getting back to that issue (and leaving for later chapters the “Cambrian explosion” of life that occurred when the giant snowball finally melted), I like the way Morton resolves this controversy.
She writes:
Consensus may be a long way off, but in some ways, everybody might be right: Perhaps plate tectonics itself has gradually evolved to operate how it does at present over billions of years, such that it’s looked different at different times in Earth’s past.
Whatever form it has taken as the planet slowly cooled, plate tectonics certainly has kept Earth habitable, beautiful, and occasionally terrifying for billions of years.
“Thanks a lot, Plate Tectonics.” — Everybody living near an erupting fire mountain. (Note: This video is from January 2020.
At the time of writing, Taal is still restless but the alert level has been lowered to 2 on a four-point scale.)
Volcanoes mess up that otherwise perfect symmetry of water, carbon, and rock cycles in so many ways.
But if they didn’t, would the Earth’s balanced energy budget have anything to spare for Life?
Let’s find out more about that in the next chapter.
Featured image: Paco Como/Shutterstock
Sources:
Akhmetiev, M. A., and Beniamovski, V. N. 2009. Paleogene floral assemblages around epicontinental seas and straits in Northern Central Eurasia: proxies for climatic and paleogeographic evolution. Geologica Acta. 7(12):297–309.
Agustí, J., and Antón, M. 2002. Mammoths, sabertooths, and hominids: 65 million years of mammalian evolution in Europe. Columbia University Press.
Corsetti, F. A.; Olcott, A. N.; and Bakermans, C. 2006. The biotic response to Neoproterozoic snowball Earth. Palaeogeography, Palaeoclimatology, Palaeoecology, 232(2-4): 114-130.
Falkowski, P.; Scholes, R. J.; Boyle, E.; Canadell, J.; and others. 2000. The global carbon cycle: a test of our knowledge of Earth as a system. Science. 290: 291–296.
Figueiró, H. V.; Li, G.; Trindade, F. J.; Assis, J.; and others. 2017. Genome-wide signatures of complex introgression and adaptive evolution in the big cats. Science Advances, 3(7): e1700299.
Hazen, R. M. 2017. Chance, necessity and the origins of life: a physical sciences perspective. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 375(2109): 20160353. https://royalsocietypublishing.org/doi/full/10.1098/rsta.2016.0353
Hoffman, P. F.; Abbot, D. S.; Ashkenazy, Y.; Benn, D. I.; and others. 2017. Snowball Earth climate dynamics and Cryogenian geology-geobiology. Science Advances, 3(11): e1600983.
Lyle, M.; Barron, J.; Bralower, T. J.; Huber, M.; and others. 2008. Pacific Ocean and Cenozoic evolution of climate. Reviews of Geophysics. 46: RG2002.
Martin, L. D. 1980. Paper 287: Functional Morphology and the Evolution of Cats. Transactions of the Nebraska Academy of Sciences and Affiliated Societies. VIII:141154. http://digitalcommons.unl.edu/tnas/287/
Moczydłowska, M. 2008. The Ediacaran microbiota and the survival of Snowball Earth conditions. Precambrian Research, 167(1-2): 1-15.
Morton, M. C. 2017. When and how did plate tectonics begin on Earth? https://www.earthmagazine.org/article/when-and-how-did-plate-tectonics-begin-earth/
NASA. 2020a. Can we find life? https://exoplanets.nasa.gov/search-for-life/can-we-find-life/ Last accessed July 12, 2021.
___. 2020b. Life in our Solar System? Meet the neighbors. https://exoplanets.nasa.gov/news/1665/life-in-our-solar-system-meet-the-neighbors/ Last accessed July 12, 2021.
___. 2021. NASA selects 2 missions to study “lost habitable” world of Venus. https://www.nasa.gov/press-release/nasa-selects-2-missions-to-study-lost-habitable-world-of-venus Last accessed July 12, 2021.
___. 2021a. Then there were 3: NASA to collaborate on ESA’s new Venus mission. https://www.nasa.gov/feature/then-there-were-3-nasa-to-collaborate-on-esa-s-new-venus-mission Last accessed July 12, 2021.
___. 2021b. Venus overview. https://solarsystem.nasa.gov/planets/venus/overview/ Last accessed July 12, 2021.
___. 2021c. The searchers: How will NASA look for signs of life beyond Earth? https://exoplanets.nasa.gov/news/1681/the-searchers-how-will-nasa-look-for-signs-of-life-beyond-earth/ Last accessed July 12, 2021.
__. 2021d. Life in the universe: What are the odds? https://exoplanets.nasa.gov/news/1675/life-in-the-universe-what-are-the-odds/ Last accessed July 12, 2021.
___. 2021f. What’s out there? The exoplanet sky so far? https://exoplanets.nasa.gov/news/1673/whats-out-there-the-exoplanet-sky-so-far/ Last accessed July 12, 2021.
___. 2021e. Mars 2020 Perseverance rover. https://mars.nasa.gov/mars-exploration/missions/mars2020/ Last accessed July 12, 2021.
___. n.d. Europa Clipper: Ingredients for life. https://europa.nasa.gov/why-europa/ingr.edients-for-life/ Last accessed July 12, 2021
Oppenheimer, C. 2011. Eruptions That Shook the World. Cambridge: Cambridge University Press. Retrieved from https://play.google.com/store/books/details?id=qW1UNwhuhnUC
Palin, R. M., and Santosh, M. 2020. Plate tectonics: What, where, why, and when?. Gondwana Research.
Prothero, D. R. 2006. After the Dinosaurs: The Age of Mammals. Bloomington and Indianapolis: Indiana University Press. Retrieved from https://play.google.com/store/books/details?id=Qh82IW-HHWAC
Sleep, N. H. 2010. The Hadean-Archaean environment. Cold Spring Harbor Perspectives in Biology, 2(6): a002527. http://m.cshperspectives.cshlp.org/content/2/6/a002527.long
Stern, R. J., and Miller, N. R. 2018. Did the transition to plate tectonics cause Neoproterozoic Snowball Earth?. Terra Nova, 30(2): 87-94.
Stern, R. J., and Miller, N. R. 2021. Neoproterozoic Glaciation—Snowball Earth Hypothesis. Encyclopedia of Geology, 546-556.
Taylor, S. R., and McLennan, S. M. 1995. The geochemical evolution of the continental crust. Reviews of Geophysics, 33(2): 241-265.
Vajda, V., and Bercovici, A. 2014. The global vegetation pattern across the Cretaceous–Paleogene mass extinction interval: A template for other extinction events. Global and Planetary Change, 122: 29-49.
Werdelin, L. 1989. Carnivoran Ecomorphology: A Phylogenetic Perspective. In Carnivore Behavior, Ecology, and Evolution, ed. Gittleman, J. L., 2:582624. Ithaca, NY: Cornell University Press.
Werdelin, L.; Yamaguchi, N.; Johnson, W. E.; and O’Brien, S. J.. 2010. Phylogeny and evolution of cats (Felidae), in Biology and Conservation of Wild Felids, eds. Macdonald, D. W., and Loveridge, A. J., 59-82. Oxford: Oxford University Press.
Wikipedia. 2021. History of the Earth. ___ Last accessed July 23, 2021.
Zachos, J.; Pagani, M.; Sloan, L.; Thomas, E.; and Billups, K. 2001. Trends, Rhythms, and Aberrations in Global Climate 65 Ma to Present. Science. 292: 686-693.
Zahnle, K.; Schaefer, L.; and Fegley, B. 2010. Earth’s earliest atmospheres. Cold Spring Harbor Perspectives in Biology, 2(10): a004895. http://m.cshperspectives.cshlp.org/content/2/10/a004895.long

3 thoughts on “Main Character: Plate Tectonics”